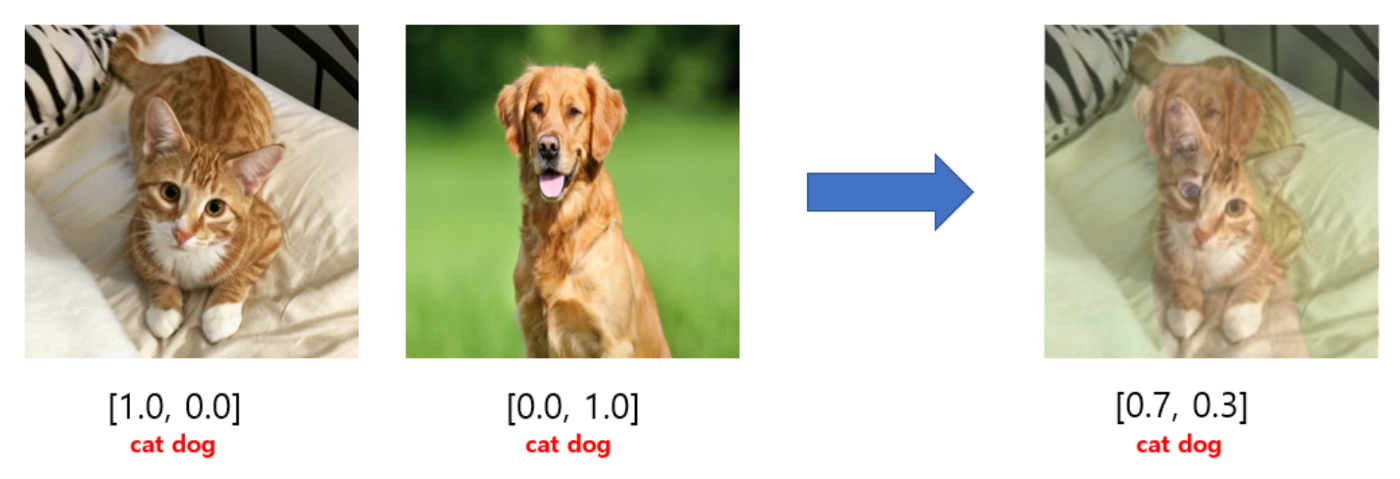
SSMix SSMix: phương pháp tăng cường dữ liệu cho bài toán phân loại văn bản Quan Chu Quoc Jan 14, 2022 • 7 min read Minh họa phương pháp mixup đối với dữ liệu ảnh.