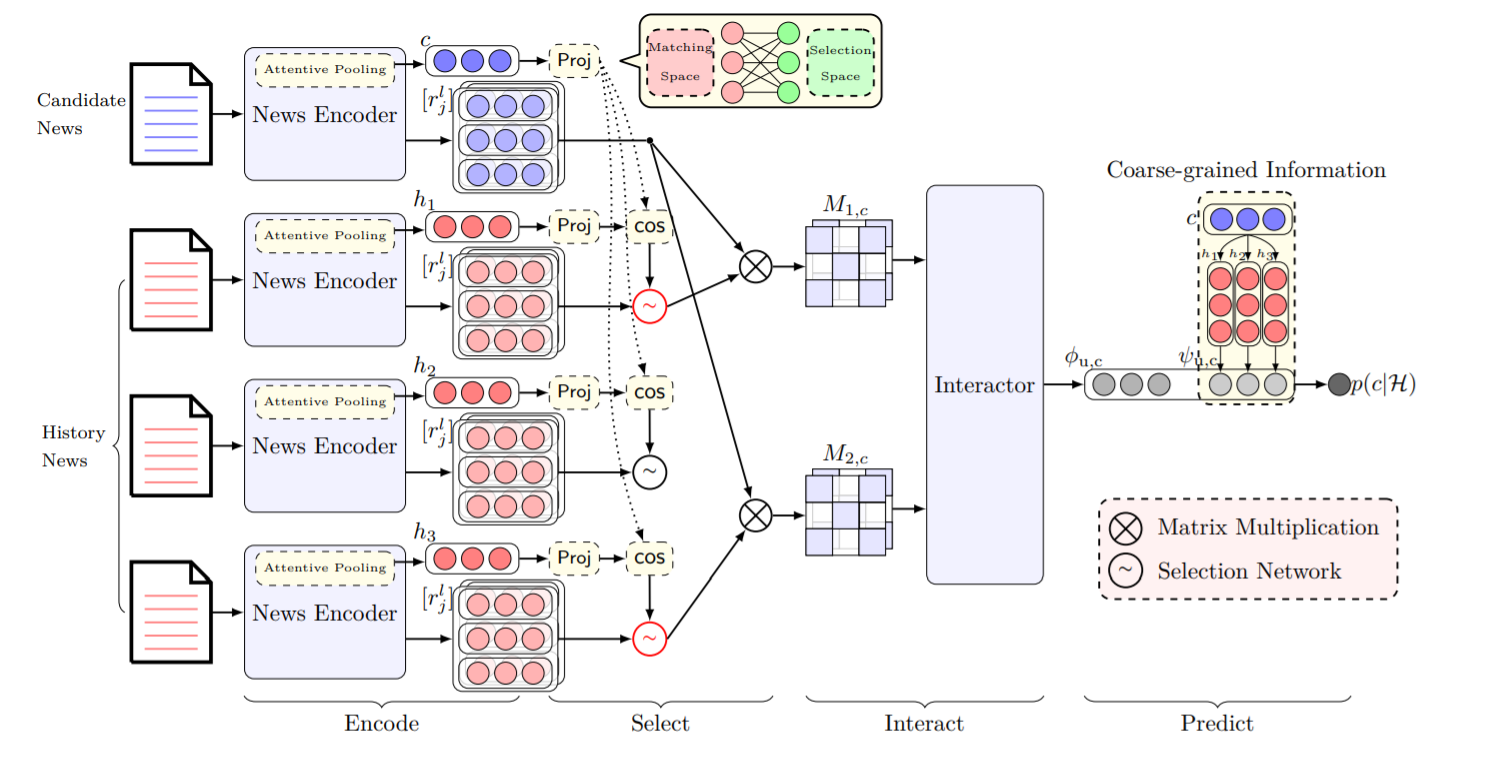
Học cách chọn các bài báo từ lịch sử đọc bài trong hệ thống đề xuất tin tức Nguyen Van Huy Feb 18, 2022 • 8 min read