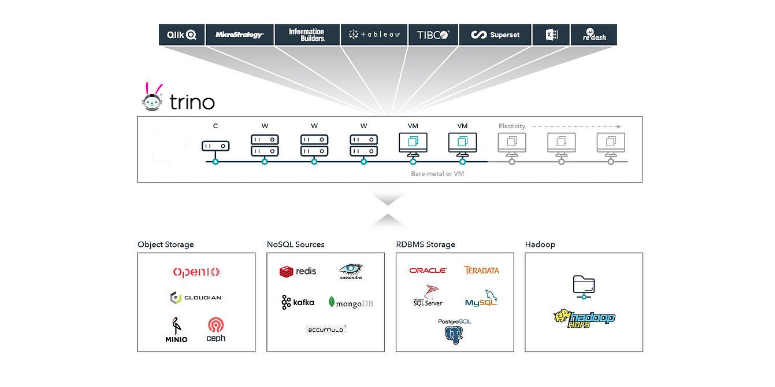
Giới thiệu Trino (Presto) — áp dụng cho bài toán làm report tại team Platform Thang Dong Jan 13, 2022 • 9 min read