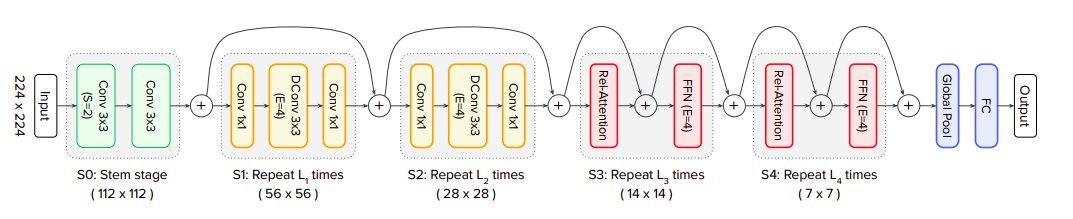
CoAtNet - Kết hợp Convolution và Attention cho tất cả các kích thước dữ liệu Dương Lê Giang Jan 26, 2022 • 8 min read Kiến trúc của mô hình CoAtNet